Bachelor thesis / UE5 + Python
AI Audio Research
I tested whether AI sound effects can react fast enough inside a playable game.
Short answer: raw generation was too late. The useful version prepares sound before the player needs it.
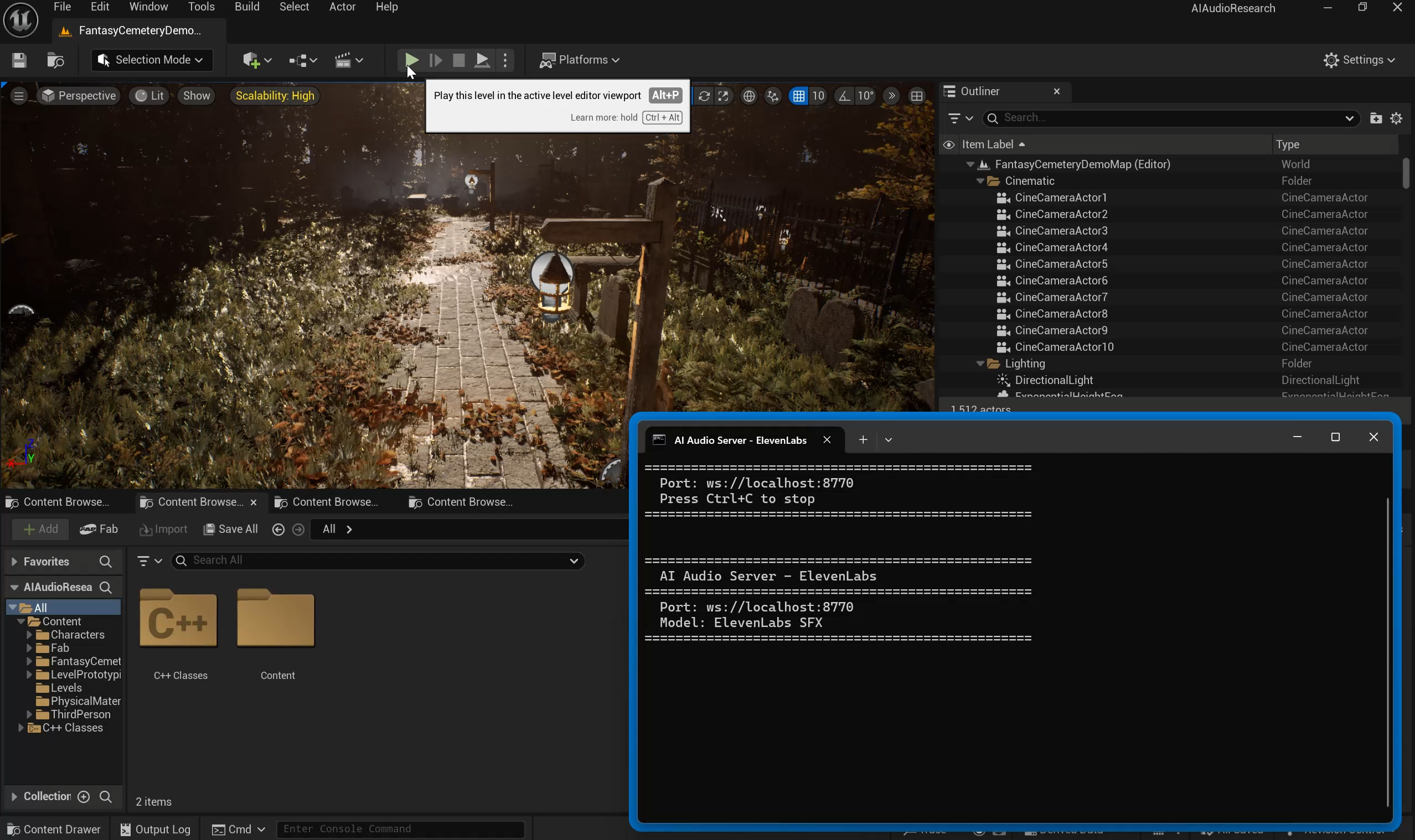
A playable UE5 prototype with a Python audio backend.
I built a UE5 client that asks a Python backend for sound during gameplay. The backend loads models, checks cache, returns PCM, and Unreal plays the result.
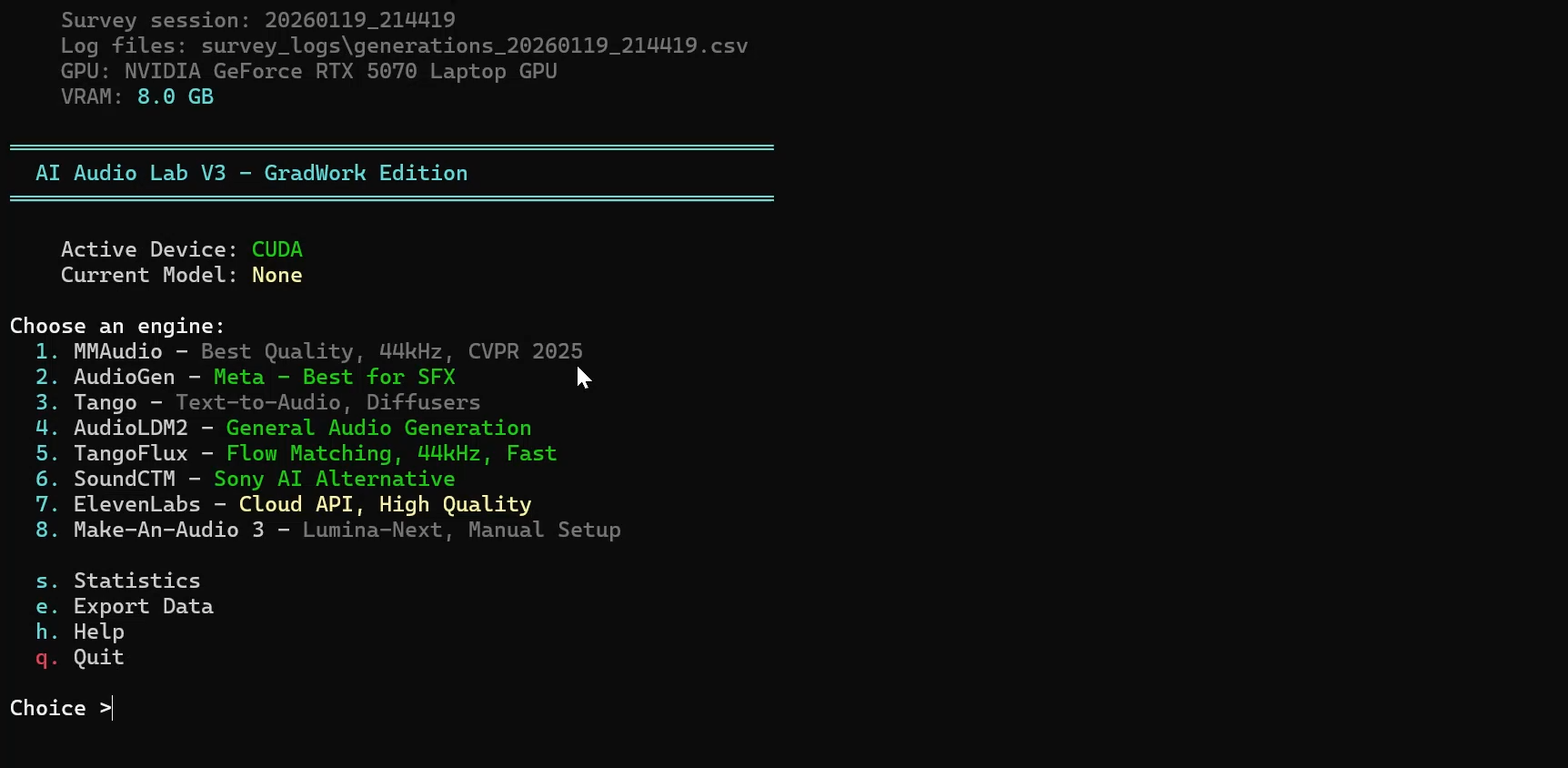
The sound could be good and still be wrong.
For gameplay feedback, timing matters more than polish. If the sound arrives after the input, the player hears the delay first.
Prepare the sound before gameplay needs it.
The practical system is simple: predict likely sounds, generate them off the critical path, cache the useful results, and keep procedural DSP ready as fallback.
Same prompt, different method.
These samples come from the presentation deck. Use them as listening evidence, not as another data table.
Low latency, but clearly synthetic.



Two recordings for context.
Unreal client: gameplay requests and playback.
Python backend: model load, cache hits, retries.
Read the Full Paper
Benchmarks, cache design, Unreal implementation notes, and failure handling.